Lecture 01 paper-1: Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics(M.Armbrust, et al., CIDR 2021)
Abstract
这篇论文认为,我们目前的传统数据仓库架构将会被一种新的架构模式——Lakehouse所取代,并且论述了Lakehouse的创新点和如何影响数据库管理领域的,最终通过TPC-DS测试(这是评估数据仓库查询性能的标准测试) 结果说明其能与当前流行的主流云数据库想媲美。
在文章的abstract部分,其实就已经很明了的说明了Lakehouse的三个核心特征
- 基于开放的、可直接访问的数据格式。如Apache Requet. Apache Parquet 是一种专为高效存储和处理大规模数据而设计的开源列式存储格式,广泛应用于大数据系统(如 Spark、Hive、Presto、Trino、Snowflake、Lakehouse 等),在CMU15445中我们也学习过列存储的压缩,效率比较高。
- 支持机器学习和数据科学
- 具有先进的性能表现
Lakehouse可以解决传统数据库存在的一些关键问题,换句话说就是传统数据库的缺点,以及Lakehouse的优点
- data staleness(数据陈旧)
- reliability(可靠性)
- total cost ofownership(TCO, 拥有成本高)
- data lock-in(数据锁定)
- limited use-case support(应用场景有限)
至于什么是传统的数据库,上面的这五个名词到底是什么意思,在文章的后面一一都进行了介绍。
Introduce
History and Challenges
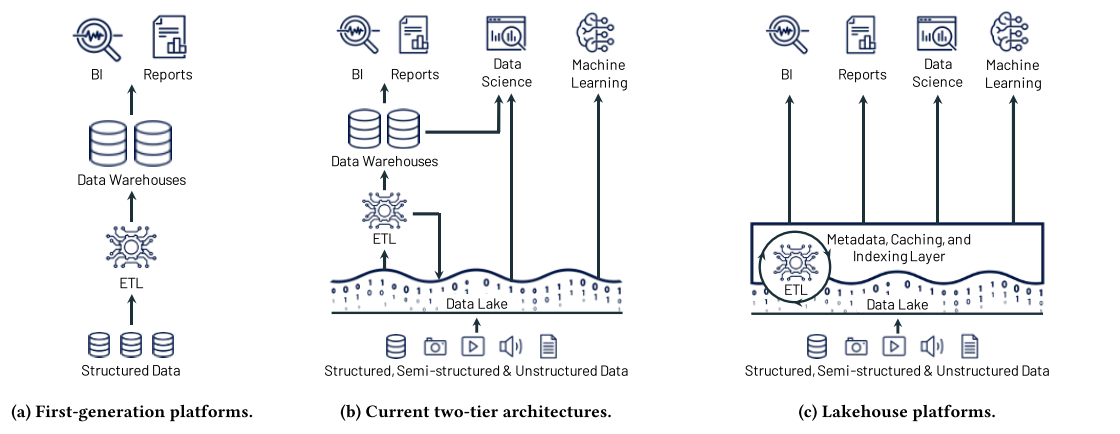
第一代数据分析平台 (first generation data analytics platforms)
首先这是data warehousing哈,不是数据库
- 目的: DSS(决策支持), BI(商业智能),换句话说, 就是帮助企业做决策
- 做法: collecting data from operational databases into centralized warehouses. 从各个业务操作形数据库中收集数据,统一存储到集中式的数据仓库中。 所谓的operational databases就是我们平时说的这些企业中用的数据库,比如说订单,库存等等.
- 优点: 第一代数据仓库使用的是schema-on-write的方式 -- 写入之前就预先定义好数据的结构,当然这样可以让后续的BI分析更加高效,因为在插入的时候就已经经过了清洗 转换 符合业务的要求, 这也算是一个优点吧我感觉
- 挑战: 第一代数据仓库面临着两个大的问题: 计算资源和存储资源绑定, 不支持非结构化数据
- 计算和存储绑定: 通常企业都是在内部部署数据仓库,自己买服务器等等(我之前也见过), 这就有两个问题,其一是随着时间的增长,数据会不断增长(当然我感觉企业会选择删除嘛?但重要的肯定不会啊), 其二是必须应对用户访问高峰,也就是哪怕平时有部分资源是闲置的,也要一直付费 -> 成本高 资源利用率低
- 不支持非结构化数据, 传统的数据库处理的内容都是数字,字符串,日期等等,但现代业务中很多PDF文档,图像,语音等等就显得无能为力了。
第二代数据分析平台(second generation data analytics platforms)
第二代数据分析平台将原始数据存入了Data Lake(数据湖).
数据湖是一种较低成本的存储系统, 通过file API来管理数据,使用的也是前面所提到的通用的开放的文件格式Apache Parquest, 这里还提到了一种叫ORC, 这两种都是列式存储格式,非常适合大数据分析
最早是从Apache Hadoop开始的,采用的是Hadoop的分布式文件系统(HDFS),后文也会提到,这是一种本地的分布式文件系统, 这里的主要思想就是,不在乎数据是什么,先存进去再说
schema-on-read架构,这与第一代仓库使用的schema-on-write架构不同,schema-on-read架构是读取数据时才解析结构,好处就是灵活低成本存储任何数据(包括非结构化), 坏处就是数据质量,数据处理,数据治理的问题还得给后面的环节。
具体的做法就是一小部分数据会从Data Lake中扔进(ETLed)下游的数据仓库中, 在这里文中举了一个例子是是Teradata.
首先ELTed是什么? -- Extract(提取) - Transform(转换) - Load(加载)
我查了一下Teradata,其实Teradata是第一代数据分析平台的代表作之一,所以说第二代数据分析平台最终还是ELT进传统仓库,才能被BI工具使用
但是 数据湖中的数据可以被机器学习平台等各种分析引擎直接访问
cloud data lacks
2015年开始,从本地Hadoop(HDFS)像云端迁移, 出现了一种更主流的架构two-tier architecture(数据湖+数据仓库的两层架构)
选择云存储的好处在于
- 数据持久性
- 地理复制: 在多个数据中心备份
- 成本低
但其余架构和第二代数据平台完全相同
事实证明,这是现在最主流的架构,几乎所有的世界前五百强企业都在用
The Challenges of two-tier architecture
虽然当前主流数据架构看上去很便宜,但是问题是他多了一个步骤(先ELT到data lack,在ELT到data warehouse),这会导致复杂,延迟,多了一个可能出错的环节的问题。除此之外,事实证明,对于机器学习等高级分析来说,data lake和data warehouse都不是理想的解决方案
现在的主流的two-tier architecture有下面的问题(这也是不是理想方案的原因):
- Reliability(可靠性差): 在data lack 和 data warehouse 中ELT,导致数据可能不会完全一致
- Data staleness(数据不新鲜): 这是延迟导致的,这个延迟可能长达数天,并且原文引用了数据做为依据
- Limited support for advanced analytics(难以支持高级分析). 这里的核心问题是企业希望仓库数据进行机器学习,用来预测一些东西。但是传统仓库不支持直接建模。那么现在其实就有两种选择:
- 其一是把数据导出为文件,比如CSV,再交给ML系统处理,那就又多了一步ETL
- 其二是直接对data lake进行分析 就失去了仓库的优势功能
- total cost of ownership(总拥有成本高): 用户要付两份钱,一份是data lake中的数据,一份是复制到warehouse中的数据;除此之外,ETL的成本也是一个问题。商业数据库的专有格式的数据锁定导致了迁移也会耗费巨大的成本。
Solution
straw-man solution
文中还提到了一种稻草人式的解决方案,主要思想是完全去掉数据湖,把所有的数据存进一个”存算分离”的现代化数据仓库。
所谓的稻草人的意思就是看起来能解决问题,但实际缺不太可行的方案
文中给出了不太可行的原因
- 还是无法很好的管理非结构化数据
- 无法提供快速直接的数据访问能力
所以,最终引出了this paper所提出来的architecture -- Lakehouse
In this paper, we discuss the following technical question:
is it possible to turn data lakes based on standard open data formats, such as Parquet and ORC, into high-performance systems that can provide both the performance and management features of data warehouses and fast, direct I/O from advanced analytics workloads?
核心的问题就是,基于开放格式的数据湖,改造一种高性能系统,使其具备数据仓库的性能和管理能力,又满足高级分析任务的快速IO要求
换句话说就是,拥有
- 数据仓库的能力(ACID, 高性能查询)
- 数据湖的能力(结构化,非结构化数据,便宜)
- 机器学习 数据科学的能力(快速,直接读写原始数据)
文章中说认为Lakehouse的时机成熟,并且列举了三个原因来解释为什么现在是Lakehouse架构发展的最佳时机,其实这也对应了本文中心思想的第一句,是说 认为目前的传统数据仓库架构将会被一种新的架构模式——Lakehouse所取代这个观点。
Reason 1: Reliable data management on data lakes
传统data lake的问题:管理"文件堆" --> 所以缺乏数据仓库具备的高级功能(如事务管理,回滚, 零克隆拷贝)
新技术Delta Lake & Apache Iceberg的出现: 给Parquet/ORC加了事务层和元数据管理 -> data lake 具备了像数据仓库一样的写入原子性等等 -> in other words, data lake 像 仓库一样可靠了
所以说带来的改进就是 lakehouse中的ETL步骤会变少,因为分析人员可以直接, 轻松访问data lake中的原始表
Reason 2: Support for machine learning and data science
首先一点,由于机器学习系统本身就支持直接读取Parquet, ORC等数据湖中的开放格式,所以Lakehouse天然就适合机器学习。
此外,现在多数系统采用DataFrame作为操作数据的抽象,通过声名性DataFrame API,可以在ML工作负载中执行数据访问的查询优化。也就是说,Lakehouse可以将SQL优化能力带给ML,使得训练更快
Reason 3: SQL performance
传统仓库 vs. Lakehouse
- 传统数据仓库(Redshift, Snowflake)内部是专有格式,意味着可以彻底优化底层
- Lakehouse用的是开放格式(Parquet, ORC),劣势
文章提到的Solution是可以通过一系列优化技术
- 维护辅助数据
- 改进文件布局和分区策略
来大大提升在Rarquet/ORC上的SQL查询性能
但是文章到目前为止还没有说是哪些优化技术
除此之外,我觉得辅助数据 可能是一些索引,或者聚合函数所要用的哪些统计信息等等,以及一些元数据
Motivation: Data Warehousing Challenges
Challenge 1: data quality and reliability.
其实还是数据质量和可靠性的这一点
文中说数据管道(data pipelines)现在本来就很难实现, 现在的two-tier data architecture 更是增加了这一复杂性,因为数据湖和仓库使用的数据类型可能不同,SQL语法不同,数据存储格式不同(一个可能标准化,一个可能非标准化)
这就不如第一代同种情况下传输的可靠了
Challenge 2: staleness
说白了就是延迟 前面介绍过 会导致很多系统 比如说推荐系统 可能失效
但是文中这里补充说了一个 可以选择流处理管道来缓解延迟, 但比批处理更难开发和运维,落地困难。
Challenge 3
现在非结构化的数据(图像, 传感器, 文档)越来越多, SQL及其API不支持
Challenge 4
machine learning 和 data science 对现在的data lake 和 data warehouse并不友好,原因是因为先来machine learning 和 data science一般都用在非SQL的编程语言上(比如我们经常用的是python), 并不能高效运行在ODBC / JDBC接口支行
作者认为:为 ML 系统提供对开放数据格式的直接访问能力是最好的支持方式。
Existing steps towards Lakehouse
其实前面也提到过,作者认为,现有产业趋势已经在朝Lakehouse过渡了
Trend1: 几乎所有的数据仓库都增加了对Rarquet和ORC格式的外部表的支持
换句话说,就是现在所有的主流数据库都支持通过"外部表" 连接到Rarquet/ORC, 这使得用户可以在SQL中直接查询数据湖中的数据
但这没有解决实质性的问题: 没有改善data lake的管理难题,也没有消除ETL的复杂性,数据时效性等
除此之外,在实践中发现,性能不好,因为数据库一般都是对其内部的规则化类型进行了优化的。
Trend 2: 出现了像Spark SQL, Presto, Hive, Athena 这种直接可以跑在data lake上的系统
这就是说,他跳过了传统的数据仓库,所以问题就是 data lake并不能像数据仓库一样存在ACID事务,索引等等的管理机制,总结来说,就是他们没法实现和数据仓库一样的性能和可靠性
The Lakehouse Architecture
首先下定义了
We define a Lakehouse as a data management system based on low-cost and directly-accessible storage that also provides traditional analytical DBMS management and performance features such as ACID transactions, data versioning, auditing, indexing, caching, and query optimization.
什么是Lakehouse
- 低成本,可直接访问的存储
- 同时提传统数据库DBMS的关键管理和性能功能
- ACID事务
- 审计(Auditing)
- 索引(index)
- 缓存(Caching)
- 查询优化(Query Optimization)
所以说Lakehouse想干的事情就是融合data lake和data warehouse的优势
- data lake的低成本,开放格式,多系统可访问
- data warehouse的强大的管理能力和高效的分析查询
所以说关键在于能否兼得
不过文章也提到了一个问题,Lakehouse支持直接访问数据意味着放弃了一部分数据独立性
什么是数据独立性,指的是应用不需要知道数据的物理结构和存储细节,DBMS 会做抽象和优化。
而Lakehouse会直接操作底层的数据格式,这一定程度上打破了抽象
同时文章指出,Lakehouse特别适合云计算场景: 不同的计算应用程序可以在完全独立的计算节点上按需运行(例如用于ML的GPU集群)同时直接访问相同的存储数据.
- 存储可以在S3, GCS, ADLS等地方
- 计算可以是
- Spark集群处理SQL
- GPU集群处理ML
这些异构计算任务可以按需启动,共同访问相同的数据,无需复制
除此之外,也可以在本地上比如前面提到的Hadoop的HDFS
然后提到了一种可行的Lakehouse设计方案,基于业界的三大技术突破。
主要组成有
- Delta Lake: 数据湖+事务版本控制
- Delta Engine: 支持高性能SQL查询
- Databricks ML Runtime: 面向机器学习的运行时支持
但是文章也提到了,本文实现的是基于Rarquet,但也可以使用其他的开放格式,Lakehouse是一个开放框架,而不是固定实现
Implementing a Lakehouse System
The first key idea we propose for implementing a Lakehouse is to have the system store data in a low-cost object store (e.g., Amazon S3) using a standard file format such as Apache Parquet, but implement a transactional metadata layer on top of the object store that defines which objects are part of a table version
first key: object store + transactional metadata
obejct store: 对象存储(Amazon S3) + 标准文件格式(Apache Rarquet)
transactional metadata: 那些文件属于哪个表版本, 谁是当前有效数据。 当然这是管理而不是存储真正的数据
-> 在事务元数据层 ACID, 版本控制;大量数据保留在低成本对象存储S3中.客户端仍然可以直接读取这些 Parquet 文件,无须复杂中间处理
成功案例: Delta Lake 和 Apache Iceberg
state-of-the-art performance...
光靠transaction metadata并不能实现高性能的SQL查询..
文中首先提了data warehouse做的一些优化:
- storing hot data on fast devices such as SSDs
- maintaing statistics 数据库中有很多统计数据和元数据,甚至还有直方图 在CMU15445中都提到过
- building efficient access methods such as indexes. access methods这个词,包括多种索引等等再CMU15445也提到过
- co-optimizing the data format and the compute engine. 数据格式和计算引擎的优化
不过lakehouse是完全摒弃了传统的数据库的,但是这些方法也能借鉴。唯一一个没法借鉴的是不能借鉴传统数据库通过更改格式进行格式优化,因为lakehouse使用的是开放的格式
那么也就是说lakehouse可以
- caching
- 建立索引,统计数据等辅助结构
- 优化数据文件的布局顺序
->这样就可以在开放格式的前提下,做到类仓库的SQL性能
DataFrame API for ML and DS
大多数的ML系统,都支持使用DataFrame API来进行预处理
后来我查了一下,DataFrame就像表格形式的数据结构,许多ML和数据分析系统,比如说TensorFlow, PyTorch,Spark, Pandas都会先使用DataFrame做好数据清洗,转换,筛选等与处理步骤。
文章后面其实也介绍到了,DataFrame是由R和Pandas最早普及开的,他们提供了一个表格抽象,支持各种转换操作符(filter,group by, join),这些操作可以对应到关系代数中的基本操作,也就是说他们和数据库的优化逻辑是兼容的
也就是说,如果这些操作是声明式的,比如Spark SQL就把DataFrame API做成了声明式(declarative)的,那么用户写的操作并不立即执行,而是最终把这些操作传给优化器,由优化器做全局优化后再执行。
这就像 SQL 查询优化器在执行前会先对 SQL 查询做逻辑计划和物理计划一样。这种方式能合并多个操作、减少扫描、提前过滤、复用中间结果等
所以说,这些DataFrame API可以很好的利用Lakehouse的新特性,比如缓存和辅助结构 加快机器学习的预处理阶段
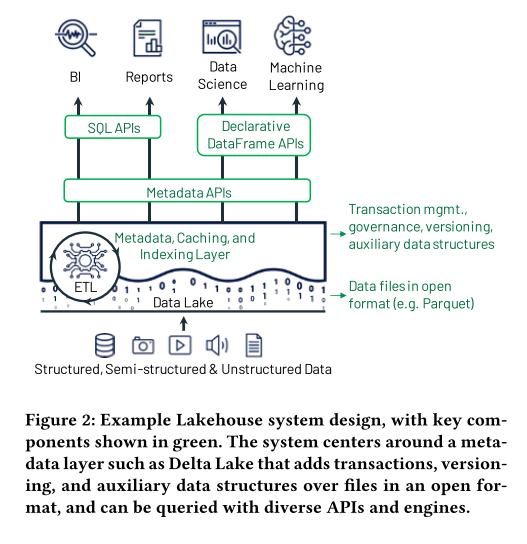
Metadata Layers for Data Management
The first component that we believe will enable Lakehouses is metadata layers over data lake storage that can raise its abstraction level to implement ACID transactions and other management features.
实现Lakehouse的第一关键能力就是 在 data lake上加一个metadata layers,提升抽象层次,实现ACID事务等其他功能
why? 为什么需要元数据层?
像Amazon S3或 HDFS这样的data lake, 本质上只是文件系统或对象存储结构,只能提供存文件和取文件的低级操作 -- 更新一个这样的操作,如果设计多个文件,没法保持原子性
Apache Hive ACID
Hive最早引入了ACID,但是使用一个数据库(OLTP DBMS), 记录表的文件元信息(比如这个文件在哪里)
Delta Lake
2016, Databricks
把事务日志也写在对象存储中,而且日志格式也是Parquet
能支持每个表包含数十亿个对象,可扩展性很好
Apache Iceberg
started Netflix
类似Delta Lake, 只不过支持Parquet,ORC文件格式
Apache Hudi
started Uber
强调对流式写入的支持,但不支持多用户并发写入
-> 这些系统相较于原始的Rarquet, ORC文件湖, 性能好 而且提供
- ACID事务
- zero-copy cloning 零拷贝克隆 -- 后面也会讲什么是zero-copy cloning
- time travel -- 其实就是支持版本回滚
- zero-copy conversion
zero-copy cloning and zero-copy conversion
把已有的 Parquet 数据目录转换为 Delta 表,不动数据,只加元数据日志, 数据湖迁移更加简单,这是zero-copy conversion
在 Delta Lake 中复制一个表/子集/版本,不复制底层文件,只复制事务日志引用,这是zero-copy cloning
data quality enforcement
数据质量控制
举例 Delta Lake
- schema enforcement: 模式强制,要求写入的数据结构必须符合表定义的schema, 否则拒绝
- constraints API: 约束接口,事实上其实就是字段取值约束
客户端能够自动处理异常数据,拒绝or放入"特殊区域"(eg quarantine文件), 手动确认后再导入
-> 增加了数据管道的可信度 稳定性
data governance
数据治理功能
- Access Control: 访问控制 -- 权限
- Audit Logging: 审计日志
Future Directions and Alternative Designs
Challenge 1: 当前的设计是Delta Lake把事务存在了对象管理中,当然优点是无需额外的系统或者是环境,方便管理,可用性高。但是对象管理的写入延迟高,导致每秒事务数量受限
Challenge 2: 目前只支持代表事务,缺少跨表事务支持。目前主流的系统 Delta, Iceberg, Hudi都仅支持代表ACID事务.
Challenge 3: 事务日志格式,目前为Json/Parquet, 但可以采取优化为更紧凑,更高效的结构(比如二进制?)
Challenge 4: 对象大小, 数据太小会导致元数据爆炸,数据太大不利于并行处理 -- 需要权衡
SQL Performance in a Lakehouse
Perhaps the largest technical question with the Lakehouse approach is how to provide state-of-the-art SQL performance while giving up a significant portion of the data independence in a traditional DBMS design.
文中认为最大的技术问题之一是 在缺乏数据库data independence(数据独立性)的情况下,如何依然做到state-of-art SQL performance.
什么是数据独立性?
传统数据库中,应用程序只关心SQL查询,而不关心底层数据是怎么存的,数据库系统可以自由决定数据的结构,比如页结构,索引策略来优化性能
但在Lakehouse, 为了ML, 需要暴露数据的存储格式作为公开API,这就牺牲了一部分数据独立性
当然是否能做到state-of-art SQL performance 依赖于很多因素,文章中列举了两个关键点
其一是缓冲
其二是替换现有的文件格式,是否能用最新的,更高效的格式来替代
所以最大的问题是,一旦选定了对外的开放数据格式,不能随意更改数据格式,所有优化手段都要在不改文件格式的前提下进行
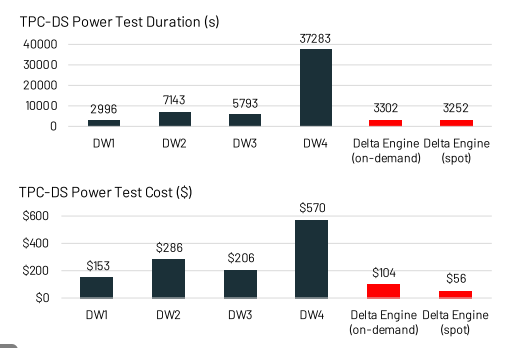
文章提出了三类"与格式无关"的优化手段,并在Databricks的Delta Engine进行了实际验证,效果与顶级云数仓媲美
Caching
当使用Delta Lake这样的事务元数据层时,Lakehouse可以把文件缓存在更快的处理节点上(SSD,RAM). 因为什么? 因为zero-copy, 而且每次查询都可以查询事务日志,确保缓存的数据是最新版本。
除此之外,缓存内容还可以是transcoded format(转码后的版本), 比如部分解压等在传统数据仓库中的各种优化
Auxiliary Data
辅助数据结构
文中提到了很多种辅助数据结构
- min-max统计信息, 存在 Delta Lake 的事务日志 Parquet 文件中, 有的时候可以用于跳过不相关的数据文件
- bloom filter索引(布隆过滤器): CMU15445提到过,快速判断某个值在不在文件中
- 多索引结构
Data Layout
数据排序方式可以被优化
- record ordering
- 可以实现类似传统数据库聚簇索引那样的排序
- 也支持space-filling curves(空间填充曲线)排序 比如Z-order, Hilbert曲线
整体:
- 热数据: 缓存 支持复杂查询 低延迟
- 冷数据: 布局,辅助数据 最小化I/O
Future Directions and Alternative Designs
Future 1: 目前主流的格式是Apache Parquet和Apache ORC,但它们原本是为离线批处理设计的,并不完美适配现代 Lakehouse 的要求, 目前可能需要具备适应灵活布局能力,更易构建索引,更适合现代硬件(如列式内存, GPU加速)的新格式. 但这是一个长期的研究问题,因为新的格式无法短期内被大量的处理引擎采纳
Furture 2: 继续挖掘缓存,索引,布局优化策略.
- caching
- 缓存什么? 按什么维度缓存?
- 热数据预测?
- auxiliary structures
- data layout
Efficient Access for Advanced Analytics
像机器学习训练、图分析、统计分析这类代码,通常使用Python的命令式代码编写的,没法作为SQL运行,所以也很难被SQL优化器加速
Solution: 声明式的DataFrame API + SQL 优化器
One approach that we’ve had success with is offering a declarative version of the DataFrame APIs used in these libraries, which maps data preparation computations into Spark SQL query plans and can benefit from the optimizations in Delta Lake and Delta Engine.
把用户写的DataFrame操作转换为Spark SQL查询计划,并可以在Delta Lake和Delta Engine的优化中收益.
Spark的查询规划器将用户DataFrame计算中的选择和投影直接推送到每个数据源读取的“数据源”插件类中,比如只选了 df["user_id", "age"],Spark 不会加载整个表,Spark 会告诉 Delta Lake 插件“只加载这两列”,从而减少 IO 和解码开销。
也利用了前面的缓存,数据布局,数据跳过来优化读取,从而加速
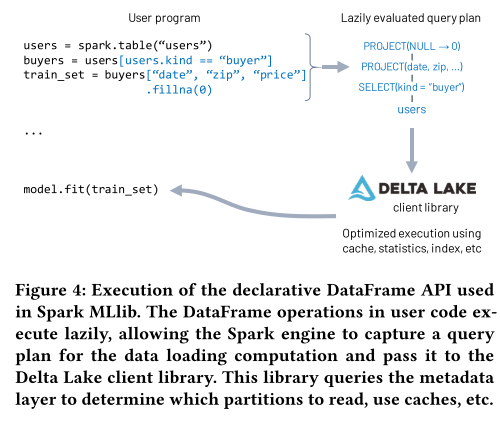
图中的整个过程是这样的:
users = spark.table("users")
buyers = users[users.kind == "buyer"]
train_set = buyers[["date", "zip", "price"]].fillna(0)
这段代码使用了PySpark的DataFrame API来从Delta Lake中读取"user"表,过滤出 kind == "buyer" 的行;选取三列 date, zip, price;用 0 填充空值(fillna(0))
Spark的lazy evaluation(懒执行)并不会立即执行每一行代码,而是构建一个查询计划
这个查询计划也不会立即运行,而是等待触发操作在执行
当Spark真正用数据的时候,比如model.fit(train_set)的时候,会将这个查询计划传递给Delta Lake.
Delta Lake会利用Metadata layer来确定那些文件分区需要读取,能否直接从缓存读取,是否有统计信息或者索引加速
但很多ML框架没法做查询下推,像tf.data这样的API更关注在CPU/GPU 异构加载和数据预处理 + GPU 训练 的流水线式并行,不会把“只读某几列、只要满足某条件的数据”等语义下推到底层,这就需要 Lakehouse 专门优化数据加载与 GPU 计算之间的配合。
Future Directions and Alternative Designs
除了前面提到的现有 API 和效率优化问题之外,我们还可以探索截然不同的数据访问接口设计方式,用于支持机器学习。例如,最近的研究提出了“因式分解机器学习(factorized ML)”框架,将机器学习逻辑直接嵌入到 SQL 的 join 操作中,并探索将传统 SQL 查询优化技术应用于 SQL 实现的 ML 算法。
我们仍然需要一套标准接口,以便数据科学家能够充分利用 Lakehouse(或数据仓库)中的强大数据管理能力。在 Databricks,我们将 Delta Lake 与 ML 实验追踪平台 MLflow 集成,使数据科学家可以轻松地记录实验所使用的表版本,并在之后复现该数据版本。
此外,业界正在兴起一种新的抽象层——特征仓库(Feature Store),用于存储和更新机器学习应用中使用的特征,这类系统如果基于 Lakehouse 的标准数据库功能(如事务和版本控制)将会受益匪浅。
JSON